Artificial intelligence turns brain activity into speech
For many people who are paralyzed and unable to speak, signals of what they’d like to say hide in their brains. No one has been able to decipher those signals directly. But three research teams recently made progress in turning data from electrodes surgically placed on the brain into computer-generated speech. Using computational models known as neural networks, they reconstructed words and sentences that were, in some cases, intelligible to human listeners.
None of the efforts, described in papers in recent months on the preprint server bioRxiv, managed to re-create speech that people had merely imagined. Instead, the researchers monitored parts of the brain as people either read aloud, silently mouthed speech, or listened to recordings. But showing the reconstructed speech is understandable is « definitely exciting, » says Stephanie Martin, a neural engineer at the University of Geneva in Switzerland who was not involved in the new projects.
People who have lost the ability to speak after a stroke or disease can use their eyes or make other small movements to control a cursor or select on-screen letters. (Cosmologist Stephen Hawking tensed his cheek to trigger a switch mounted on his glasses.) But if a brain-computer interface could re-create their speech directly, they might regain much more: control over tone and inflection, for example, or the ability to interject in a fast-moving conversation.
The hurdles are high. « We are trying to work out the pattern of … neurons that turn on and off at different time points, and infer the speech sound, » says Nima Mesgarani, a computer scientist at Columbia University. « The mapping from one to the other is not very straightforward. » How these signals translate to speech sounds varies from person to person, so computer models must be « trained » on each individual. And the models do best with extremely precise data, which requires opening the skull.
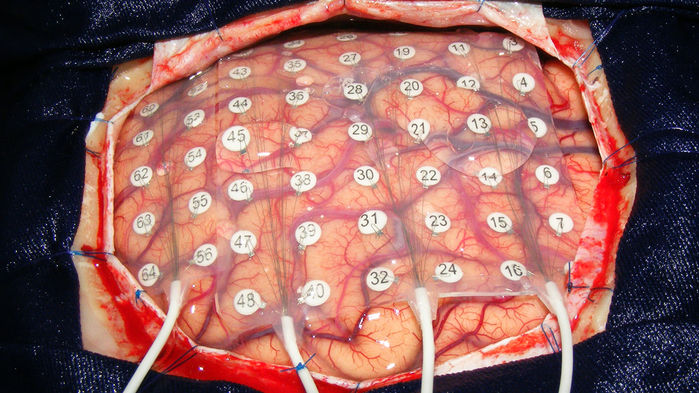
Researchers can do such invasive recording only in rare cases. One is during the removal of a brain tumor, when electrical readouts from the exposed brain help surgeons locate and avoid key speech and motor areas. Another is when a person with epilepsy is implanted with electrodes for several days to pinpoint the origin of seizures before surgical treatment. « We have, at maximum, 20 minutes, maybe 30, » for data collection, Martin says. « We’re really, really limited. »
The groups behind the new papers made the most of precious data by feeding the information into neural networks, which process complex patterns by passing information through layers of computational « nodes. » The networks learn by adjusting connections between nodes. In the experiments, networks were exposed to recordings of speech that a person produced or heard and data on simultaneous brain activity.
Mesgarani’s team relied on data from five people with epilepsy. Their network analyzed recordings from the auditory cortex (which is active during both speech and listening) as those patients heard recordings of stories and people naming digits from zero to nine. The computer then reconstructed spoken numbers from neural data alone; when the computer « spoke » the numbers, a group of listeners named them with 75% accuracy.
H. Akbari et al., doi.org/10.1101/350124
Another team, led by computer scientist Tanja Schultz at the University Bremen in Germany, relied on data from six people undergoing brain tumor surgery. A microphone captured their voices as they read single-syllable words aloud. Meanwhile, electrodes recorded from the brain’s speech planning areas and motor areas, which send commands to the vocal tract to articulate words. Computer scientists Miguel Angrick and Christian Herff, now with Maastricht University, trained a network that mapped electrode readouts to the audio recordings, and then reconstructed words from previously unseen brain data. According to a computerized scoring system, about 40% of the computer-generated words were understandable.
M. Angrick et al., doi.org/10.1101/478644
Finally, neurosurgeon Edward Chang and his team at the University of California, San Francisco, reconstructed entire sentences from brain activity captured from speech and motor areas while three epilepsy patients read aloud. In an online test, 166 people heard one of the sentences and had to select it from among 10 written choices. Some sentences were correctly identified more than 80% of the time. The researchers also pushed the model further: They used it to re-create sentences from data recorded while people silently mouthed words. That’s an important result, Herff says— »one step closer to the speech prosthesis that we all have in mind. »
However, « What we’re really waiting for is how [these methods] are going to do when the patients can’t speak, » says Stephanie Riès, a neuroscientist at San Diego State University in California who studies language production. The brain signals when a person silently « speaks » or « hears » their voice in their head aren’t identical to signals of speech or hearing. Without external sound to match to brain activity, it may be hard for a computer even to sort out where inner speech starts and ends.
Decoding imagined speech will require « a huge jump, » says Gerwin Schalk, a neuroengineer at the National Center for Adaptive Neurotechnologies at the New York State Department of Health in Albany. « It’s really unclear how to do that at all. »
One approach, Herff says, might be to give feedback to the user of the brain-computer interface: If they can hear the computer’s speech interpretation in real time, they may be able to adjust their thoughts to get the result they want. With enough training of both users and neural networks, brain and computer might meet in the middle.
*Clarification, 8 January, 5:50 p.m.: This article has been updated to clarify which researchers worked on one of the projects.